Introduction
One of the most used data structures across programming languages is a hash table, aka hash map. A hash map is similar to a conventional array, except it uses “keys” as indices rather than meaningless sequential numbering of the values. With the data organized in this way, we get quick search speeds for keys in the structure. If you’ve worked with JavaScript Object Literals ({}), Set, or Map, then you have used structures based on hash tables. But how do they work internally? How can we save key value pairs and later retrieve them?
In this lesson, you will learn how it all works, and even implement your own hash map in the next project! To start, here is a brief description of a hash map: a hash map takes in a key value pair, produces a hash code, and stores the pair in a bucket. Hash codes? Buckets? What? Don’t fret, we’ll learn all about these concepts and more. Buckle up and let’s dive in!
Lesson overview
This section contains a general overview of topics that you will learn in this lesson.
- Hash codes and how to generate them.
- Hash maps and how they work internally.
What is a hash code?
Let’s start by learning what it means to hash a value. Hashing involves taking an input in and generating a corresponding output. A hash function should be a pure function. Hashing the same input should always return the same hash code, and there should be no random generation component. For example, let’s look at a hashing function that takes a name and gives us the first letter of that name:
function hash(name) {
return name.charAt(0);
}
We created our first basic hashing function.
There is a key difference between hashing and ciphering (encryption): reversibility.
Hashing is a one-way process. Using the above example, you can make a hash code from a name, but you cannot take a hash code and revert it back to a name. If you have a name "Carlos", we can hash it to "C". But it’s impossible to reverse it from "C" back to its original form. You cannot know if it’s "Carlos", maybe it’s "Carla" or "Carrot". We don’t know.
Benefits of hashing
Hashing is very good for security. Given a password, you can save the hash of that password rather than the password’s plain text. If someone steals your hashes, they cannot know the original passwords since they are unable to reverse the hash back to the password.
Use cases
What can we do with those hashes? You have probably seen it in school where a folder is organized into smaller folders, and each folder holds information about people with the same first letter:
C:
carlos.txt
carla.txt
B:
bryan.txt
bob.txt
beatrice.txt
bella.txt
benjamin.txt
bianca.txt
If we get a new student in our school with the name "Carlos", we can run our hash function to find out which folder to place them in. hash("Carlos") -> "C" so we put "Carlos" in the directory labeled C.
You might have spotted a problem: what if our school is populated with many people whose names share the same first letter C? Then we will have a directory labeled C that holds too many names while other directories could be empty. To eliminate this duplication and better separate our students, we need to rework our hash function.
function hash(name, surname) {
return name.charAt(0) + surname.charAt(0);
}
Instead of just taking the first name letter, we take the first name and last name letters. "Carlos Smith" will have a hash code of "CS". This will spread our students among more directories and will eliminate many duplicate hash codes from being generated.
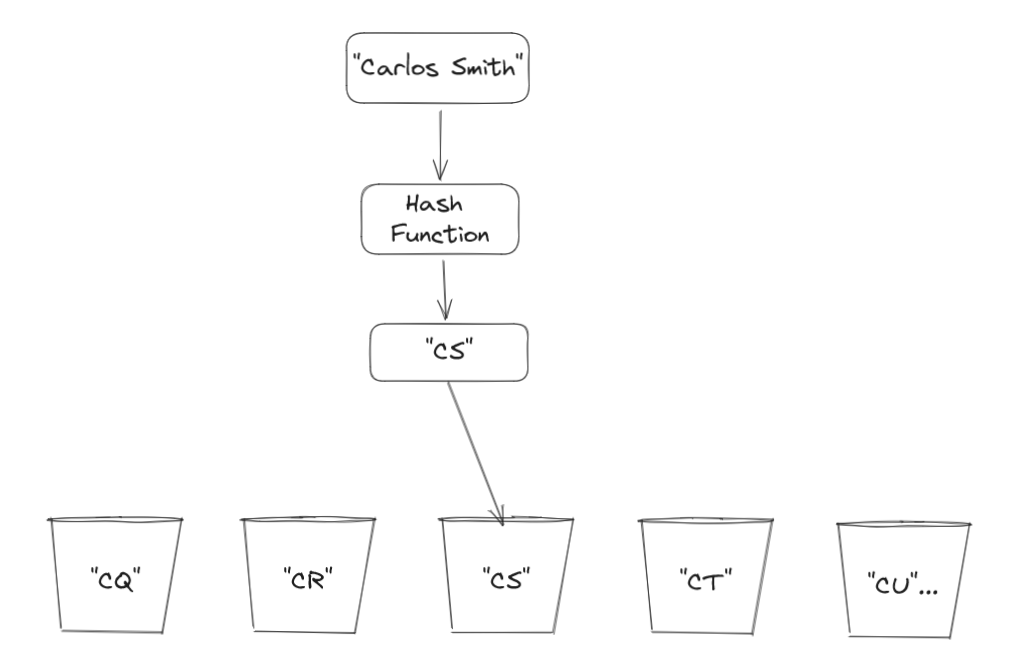
But it still doesn’t solve our problem. What if we have a common combination of first letters in students’ names? Then we will still have an imbalance in the size of the directories. We need to make it easier to find the person we’re looking for, so let’s rework our hash code.
function stringToNumber(string) {
let hashCode = 0;
for (let i = 0; i < string.length; i++) {
hashCode += string.charCodeAt(i);
}
return hashCode;
}
function hash(name, surname) {
return stringToNumber(name) + stringToNumber(surname);
}
We not only consider the first letters with this technique. Instead, we take the entire name and convert it into numbers.
You might be thinking, wouldn’t it just be better to save the whole name as a hash code? That is true. This would make it unique for each name, but in the context of hash maps, we need the hash code to be a number. This number will serve as the index to the bucket that will store the key value pair. More on buckets in the next section.
Buckets
Buckets are storage that we need to store our elements. We can consider each index of an array to have a bucket. For a specific key, we decide which bucket to use for storage through our hash function. The hash function returns a number that serves as the index of the array at which we store this specific key value pair. Let’s say we wanted to store a person’s full name as a key “Fred” with a value of “Smith”:
- Pass “Fred” into the hash function to get the hash code which is
385. - Find the bucket at index
385. - Store the key value pair in that bucket. In this case, the key would be “Fred” and the value would be “Smith”.
What if the bucket at index 385 already contains an item with the same key “Fred”? We check if it’s the same item by comparing the keys, then we overwrite the value with our new value. This is how we can only have unique values inside a Set. A Set is similar to a hash map but the key difference (pun intended) is that a Set will have nodes with only keys and no values.
This is an oversimplified explanation; we’ll discuss more internal mechanics later in the lesson.
Now if we wanted to get a value using a key:
- To retrieve the value, we hash the key and calculate the index of its bucket.
- If the bucket is not empty, then we go to that bucket.
- Now we compare if the node’s key is the same key that was used for the retrieval.
- If it is, then we can return the node’s value. Otherwise, we return
null.
Maybe you are wondering, why are we comparing the keys if we already found the index of that bucket? Remember, a hash code is just the location. Different keys might generate the same hash code. We need to make sure the key is the same by comparing both keys that are inside the bucket.
This is it, making this will result in a hash map with has, set and get.
Insertion order is not maintained
A hash map does not guarantee insertion order when you iterate over it. The translation of hash codes to indexes does not follow a linear progression from the first to the last index. Instead, it is more unpredictable, irrespective of the order in which items are inserted. That means if you are to retrieve the array of keys and values to iterate over them, then they will not be in order of when you inserted them.
Some libraries implement hash maps with insertion order in mind such as JavaScript’s own Map. For the coming project however we will be implementing an unordered hash map.
Example: if we insert the values Mao, Zach, Xari in this order, we may get back ["Zach", "Mao", "Xari"] when we call an iterator.
If iterating over a hash map frequently is your goal, then this data structure is not the right choice for the job. A simple array would be better.
Collisions
We have another problem that we need to deal with: collisions. A collision occurs when two different keys generate the exact same hash code. Because they have the same hash code, they will land in the same bucket.
Let’s take an example: hashing the name "Sara" and the name "raSa" will generate the same hash code. That is because the letters in both names are the same, just arranged differently.
We can rework our stringToNumber function so that it can give us unique hash codes that depend on where the letters appear in the name using an algorithm.
function stringToNumber(string) {
let hashCode = 0;
const primeNumber = 31;
for (let i = 0; i < string.length; i++) {
hashCode = primeNumber * hashCode + string.charCodeAt(i);
}
return hashCode;
}
With our new function we will have different hash codes for the names "Sara" and "raSa". This is because even if both names have the same letters, some of the letters appear in different locations. The hash code started to change because we are multiplying the old hash with every new iteration and then adding the letter code.
Minimizing collisions
Notice the usage of a prime number. We could have chosen any number we wanted, but prime numbers are preferable. Multiplying by a prime number will reduce the likelihood of hash codes being evenly divisible by the bucket length, which helps minimize the occurrence of collisions.
Even though we reworked our hash function to avoid the "Sara"/"raSa" collision, there is always the possibility for collisions. Since we have a finite number of buckets, there is no way to eliminate collisions entirely. Let’s try to minimize them.
Dealing with collisions
Up until now, our hash map is a one-dimensional data structure. What if each Node inside the bucket can store more than one value? Enter Linked Lists. Now, each bucket will be a Linked List. When inserting into a bucket, if it’s empty, we insert the head of Linked List. If a head exists in a bucket, we follow that Linked List to add to the end of it.
You probably understand by this point why we must write a good hashing function which eliminates as many collisions as possible. Most likely you will not be writing your own hash functions, as most languages have it built in, but understanding how hash functions work is important.
Growth of a hash map
Let’s talk about our number of buckets. We don’t have infinite memory, so we can’t have an infinite amount of them. We need to start somewhere, but starting too big is also a waste of memory if we’re only going to have a hash map with a single value in it. So to deal with this issue, we should start with a small array for our buckets. We’ll use an array of size 16.
Setting the initial size of the array
Most programming languages start with the default size of 16 because it’s a power of 2, which helps with some techniques for performance that require bit manipulation for indexes.
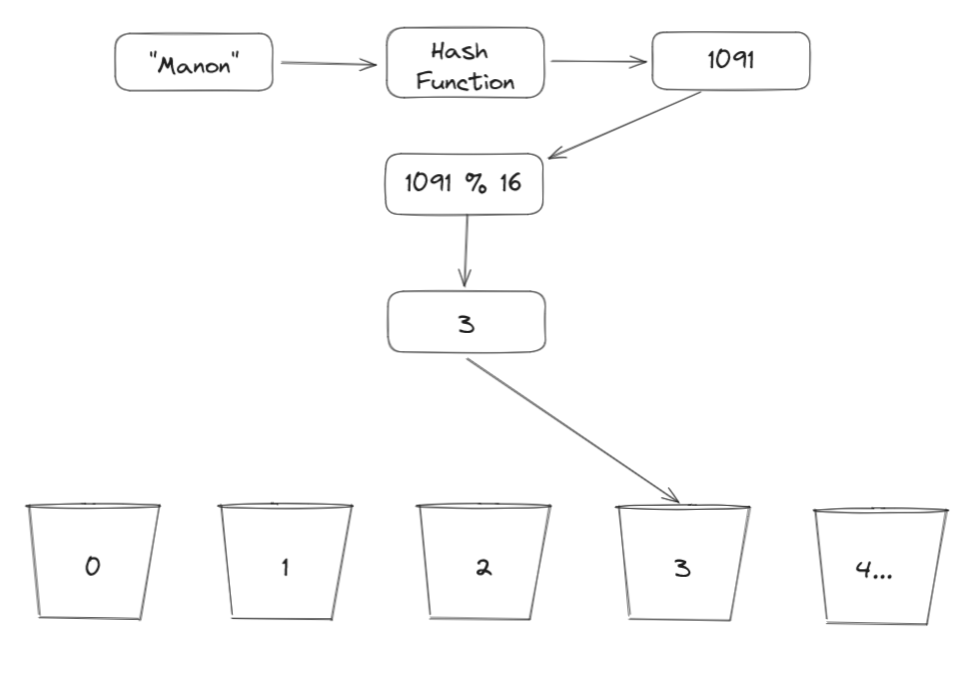
How are we going to insert into those buckets when our hash function generates big numbers like 20353924? We make use of the modulo % operation given any number modulo by 16 we will get a number between 0 and 15.
For example, if we are to find the bucket where the value "Manon" will land, then we do the following:
As we continue to add nodes into our buckets, collisions get more and more likely. Eventually, however, there will be more nodes than there are buckets, which guarantees a collision (check the additional resources section for an explanation of this fact if you’re curious).
Remember we don’t want collisions. In a perfect world, each bucket will either have 0 or 1 node only, so we grow our buckets array to have more chance that our nodes will spread and not stack up in the same buckets. To grow our array, we create a new one that is double its size and then copy all existing nodes over to the buckets of this new array, hashing their keys again.
When do we know that it’s time to grow our buckets array?
To deal with this, our hash map class needs to keep track of two new fields, the capacity and the load factor.
-
The
capacityis the total number of buckets we currently have. -
The
load factoris a number that we assign our hash map to at the start. It’s the factor that will determine when it is a good time to grow our buckets array. Hash map implementations across various languages use a load factor between0.75and1.
The product of these two numbers gives us a number, and we know it’s time to grow when there are more entries in the hash map than that number. For example, if there are 16 buckets, and the load factor is 0.8, then we need to grow the buckets array when there are more than 16 * 0.8 = 12.8 entries - which happens on the 13th entry. Setting it too low will consume too much memory by having too many empty buckets, while setting it too high will allow our buckets to have many collisions before we resize the array.
Computation complexity
A hash map is very efficient in its insertion, retrieval and removal operations. This is because we use array indexes to do these operations. A hash map has an average case complexity of O(1) for the following methods:
- Insertion
- Retrieval
- Removal
Assuming we have a good hash map written. The worst case of those operations would be O(n) and that happens when we have all our data hashes to the same exact bucket. The complexity itself surfaces because of the linked list, and O(n) is because we are traversing the linked list to insert yet again another node into the same bucket, which happens specifically because of collisions.
The growth of our hash map has the complexity of O(n) at all times.
Assignment
- Watch this video from CS50 that explains the concept of hash maps using buckets.
Knowledge check
The following questions are an opportunity to reflect on key topics in this lesson. If you can’t answer a question, click on it to review the material, but keep in mind you are not expected to memorize or master this knowledge.
Additional resources
This section contains helpful links to related content. It isn’t required, so consider it supplemental.
- This discussion goes through the usages of prime numbers in hash functions.
- The pigeonhole principle mathematically guarantees collisions when there are more nodes than boxes.
- Check out Hashing if you want to get a better fundamental understanding of hash functions.